Innerve Data Science Hackathon
Hi, We are ThandePapas
Aditya
(NSUT)
Harshit(NSUT)
Project:
(NSUT)
Harshit(NSUT)
For a visually impaired person, how can we build something to help navigate the road better?
Our task consists of two problems :
1. Direction/ Lane Predictions
2. Object detections for incoming obstructions/vehicles/people
We try here to tackle both of them using our data science models.


Technologies used :
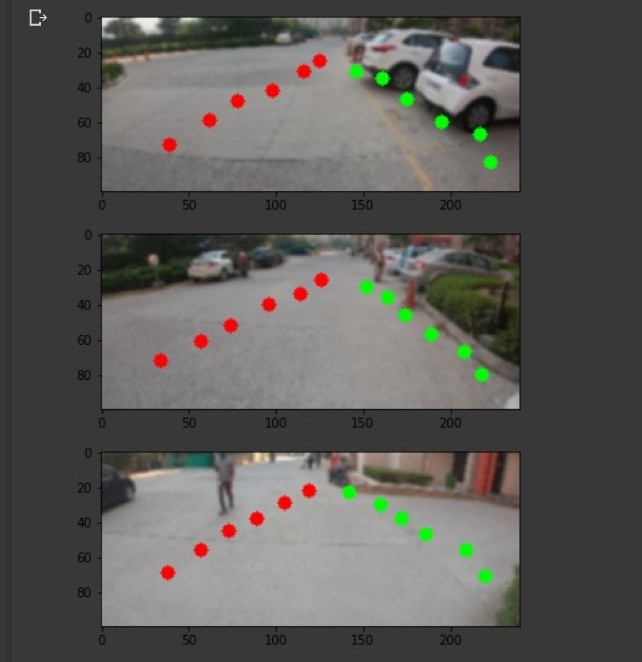
Our objective was to get the lane that is valid to walk upon.
We figured to apply hough transform to the dataset and get the vertical lines after the picture is passed through canny filter and
segmentation has been done to get the area that is best to look upon. Lastly we visualise the predictions overlayed on the original frames.
The model does find the nearest lane in the video, as seen in the videos.
It also does predict any big obstructions ahead of your POV such as :
a speed bump, a landfill, and much more.


This model detects the lanes quite nicely if it's in a straight linewith a pretty good accuracy.
Though we can still improve on the model.
There are a few demerits of the system:
1. Curved roads are not detected.
2. It sometimes gets confused by gravel roads, which can be improved to an extent by increasing the blur.
Since it's inherently an object detection task we can indeed just use a CNN (Convulutional Neural Network)
The main problem with this is what should be the output layer of the CNN.
We decided to go with 12 points having x and y coordinates.
6 points on the left and 6 points on the right.
The CNN will learn on the labelled dataset and then according to
the learned weights predict on new unseen data.
Hence the output layer is a 24 unit flat layer.
The process of labelling is done by a custom openCV program which can be found in the project directory.

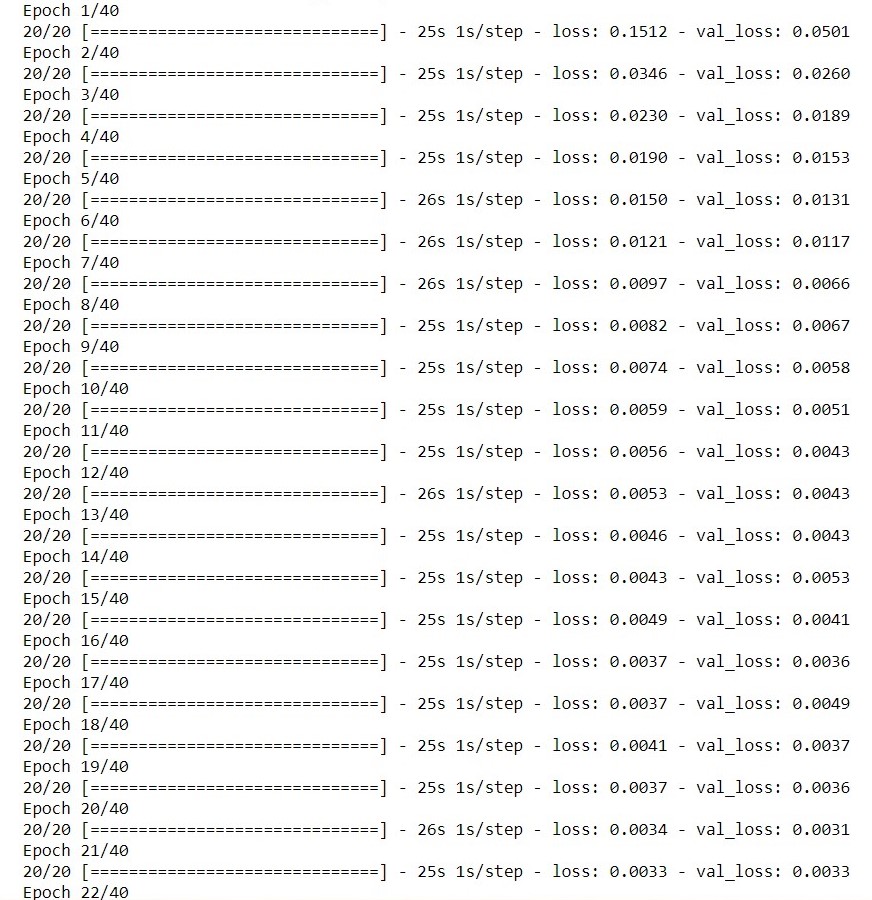
We used a fairly standard CNN model with increasing filters and decreasing size of convolutions.
We train it for 40 epochs to avoid overfitting.
The model does pretty nice provided the dataset is pretty limited and we take in account the labelling biases.
Overall it does detect the direction and where it should not go.
The loss too goes down with increasing epochs so the model is able to get the features.
The predictions are not state of art.
The dataset we had was pretty limited with less people and vehicles on roads, making it easier for the model to get good accuracy
The model could have overfit due to this.
Getting better predictions are overkill at this point without using very deep neural nets.
But the results are also not to bad to train such a model.
Alternatively we could get the weights of an already deep neural model and use transfer learning.
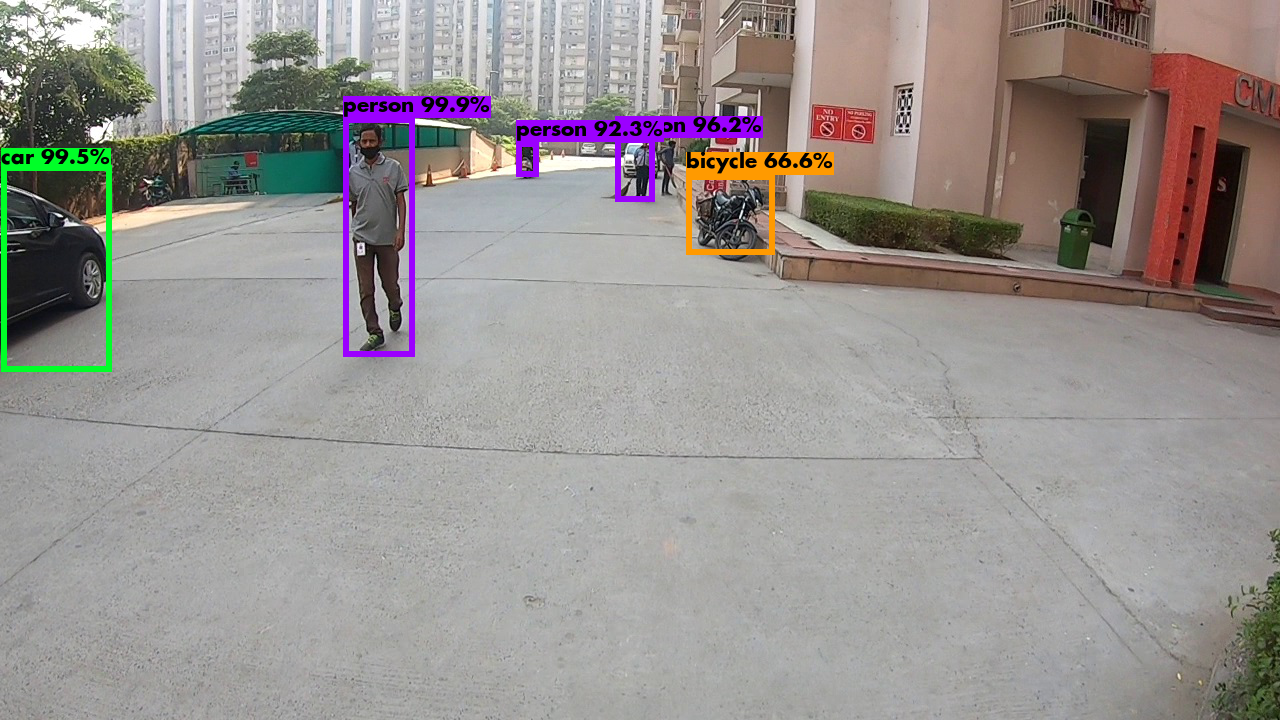
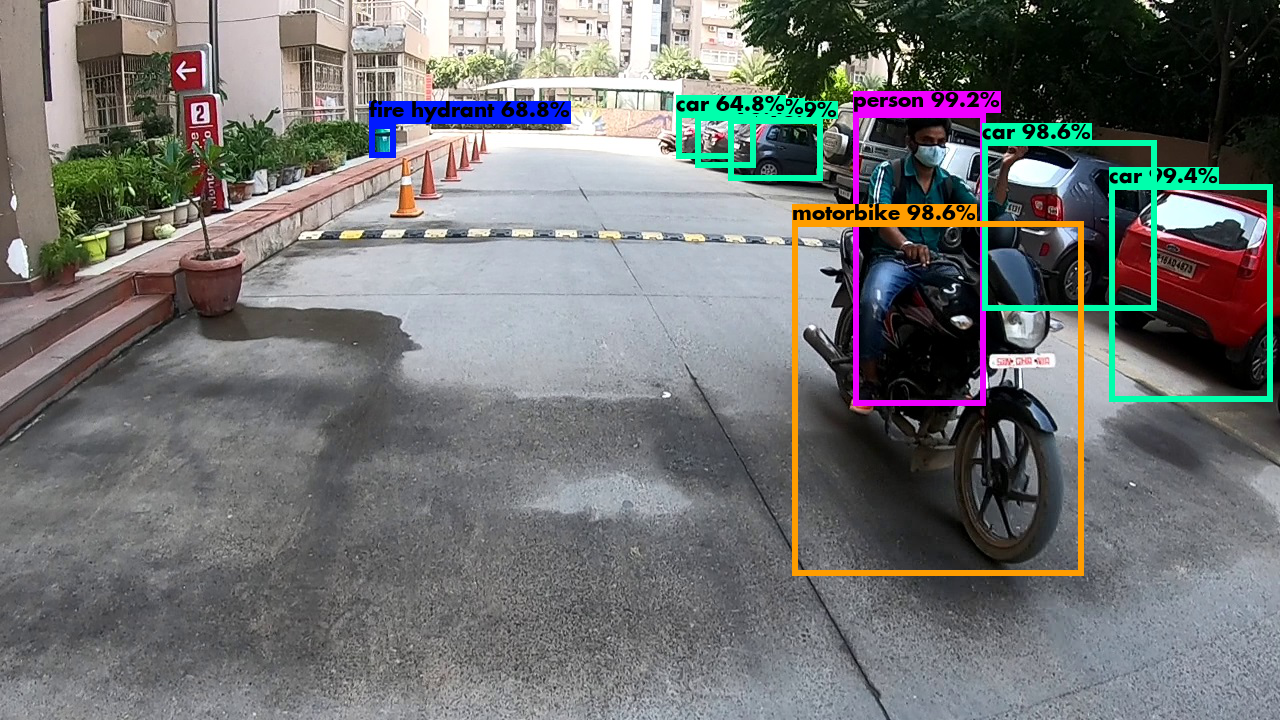
YOLO algorithm basically uses a DARKNET-53 model which is trained on ImageNet data.
Since retraining on our labels will take both time and computations, we took weights from the
open source community and built the model to get the predictions.
We did implement non-max suppression to get better bounding boxes because YOLO
gives various anchor boxes.
We give a probability threshhold to get best results
and moreover exclude overlapping data.
We further convert the output , which is given as the mid point of the anchor box and the
height and width of the image to x, y coordinates and
then plotting it using openCV overlaying on the testset.
The next steps were to deploy it via a device small enough to take the information,
and computationally cabable for predicting.
With the coming of tensorflow for native mobile applications, these are possible.
We could alternatively build a device just for this purpose.
We could essentialy build an app that takes all this data and :
1. Detects paths
2. Takes care of incoming car/person
3. Gives audio output (Text-to-speech) of where to turn, how much to turn, how much to walk.
We could essentially take even more dataset from the native device and retrain
it for even more epochs for even better accuracy.
This could prove to be a great idea for the visually impaired
and would be a help to them in the ever increasing populations.